Toward the tail end of my time at Cyft, I started seeing an existential threat to my work. All of the workflows, Claude Code slash commands, API integrations, and operational logic I'd built lived on my local machine. Scattered across files, terminals, and my own memory. If my SSD died tomorrow, a significant chunk of how I actually did my job would die with it.
And I have multiple PCs. So if I needed to hop on a plane for a work trip and access a slash command from my laptop, well, it's sitting on my desktop back home. See the problem?
So I started putting it all in a GitHub repo.
GitHub Is the Natural Home for This Stuff
GitHub turned out to be the most natural place for this stuff because what I was building wasn't documents or slide decks. It was code. Schema definitions, environment variables, context files that reference other context files. Claude Code uses a CLAUDE.md file as an operating manual, and when certain topics come up in conversation, it knows to pull in specific context files with code snippets, API endpoints, and detailed instructions for different workflows. That whole referential architecture can live in the repo.
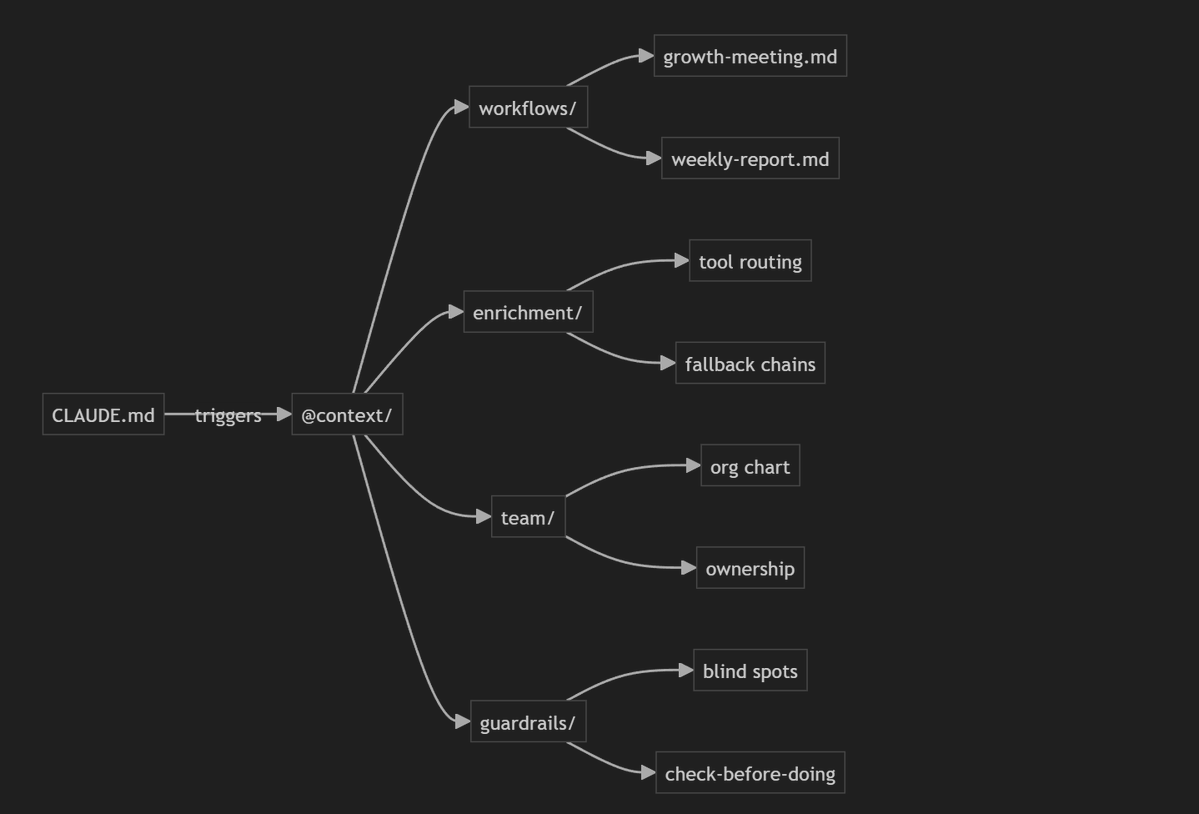
It's also a bus factor thing. If I disappear tomorrow, my team should be able to open a repo and understand how the growth meeting agenda gets built, which APIs feed it, and what quirks to watch out for.
What's Actually in the Repo
For that growth team meeting we had every Monday, I'd pull data from three places: Email Bison to get outbound performance metrics, Salesforce to get opportunity updates and deal statuses, and Typeform to get demo request submissions. Then Cursor would do the math on conversion, cold email performance, pipeline progression etc. The slash command knew which API endpoints to hit, how to format the schema, and how to compile it all into a structured agenda.
Data enrichment is another one. I've got context files that map out which tools to use for what. Apollo for this type of lookup. Firecrawl for that type of scrape. And embedded in those files is stuff that lives in my head and would be forgotten if I didn't write it down.
Ex: I was trying to pull all the finable Twitter profiles for everyone at AirOps during my pre-start prep. Claude Code checked the environment file, found Exa had an API key, and ran the search. Nothing came back. Turns out Exa can't scrape Twitter. Their bot gets blocked. But Serper.dev can find Twitter profiles because it's just hitting Google's search API, which returns a more deterministic result. Serper's not trying to crawl Twitter directly. It's pulling Google's indexed results for "site:twitter.com [person name]."
That's the kind of thing you'd normally burn time on, get pissed off at, and then forget three months later. Now it's in a context file. Next time Claude Code tries to find social profiles, it already knows the routing. This is essentially helping me realize the second brain premise of AI.
Prepping for a New Job... With Agents 🤣
When I accepted the offer at AirOps, I had about three weeks before my start date. And I kept thinking: how do I actually hit the ground running? Not in the vague "read the company blog" way, but in a way where my AI copilot is genuinely useful from day one.
So I treated it like configuring a new operating system. I'm treating it like the Airops Co-Pilot OS.
I loaded Claude with context about my new team. Who I'm reporting to, what they care about, what they're measured on. I researched the tech stack, the challenges I'd be inheriting, the competitive landscape. All of that went into the AirOps project I set up in Claude Desktop.
I also fed it my weaknesses.
I'm not good at corporate politics. I know this about myself. I have a tendency to just go do things without checking whether someone's going to be territorial about it. So I literally told Claude: if I'm asking you about Salesforce CLI stuff, or anything else that might be sensitive, stop me and ask whether I've checked with my team first. Remind me that someone might care about this. We'll see if it will commit my responses to memory so it's not warning me every time I want to change a Salesforce configuration.
What I'm hoping will happen is that Claude will say, "hey, this touches {so and so's} domain, have you looped them in?" And I'll think, oh shit, you're right. I was about to go full cowboy.
I think most peoples default is to treat AI as an execution engine: write this email, build this report, debug this code. (If we're talking about normies it's just a fancy google search...) If you invest the time to teach it about yourself, not just your tasks, you get something qualitatively different, in my experience.
Skill Set Collapse
Software engineers have always maintained repos as portfolios. Documented their toolchains, their preferences, their architectural decisions. When they interview somewhere, there's often a field on the application that says "link to your GitHub" and the expectation that a hiring manager might actually look at it.
GTM folks haven't had that. Historically, what you took to your next job was a mental list of tools you liked. "I think we should implement Clay." "Have you heard of Leadmagic?" Maybe some email templates in a Google Drive folder. Maybe a MEDDIC cheat sheet. Surface-level stuff.
I think the skill sets are collapsing on each other.
IT people used to administer CRMs. Then we carved out this discipline called RevOps, and those folks owned the operational layer. Now, with coding agents and tools like Claude Code, we're almost circling back to something that looks more like software development or IT.
The best RevOps and growth folks have always been code-savvy to some degree. AI has just lowered the floor dramatically. You don't need a CS degree to build API integrations anymore. You need to understand the logic and be able to direct an agent to execute it.
If that's where things are headed, then the GitHub repo becomes the natural artifact of your work. Your ICP definitions. Your enrichment logic. Your meeting cadences. Your hard-won knowledge about which tools can and can't do what.
... But Will It Catch On?
If I were interviewing a GTM engineer today, I'd ask if they have a repo. I wouldn't expect it. Most people don't. But I'd ask.
Not because the code itself matters that much, but it would tell me how that person thinks about their work. Do they treat their operational knowledge as something worth codifying? Do they think in systems, or just in tasks? Have they built anything reusable, or do they start from scratch every time?
I could see this becoming more common. Not as a hard requirement, but as a "hey, if you have one, we'd love to see it" kind of thing. The same way engineering hiring evolved over time.
The growth meeting command I built at Cyft is going to look different at AirOps. Different tools, different APIs, different team cadence and meeting purpose. But the architecture transfers. I didn't start from zero. I started from a repo.